Predicting Patient Mortality Using Scikit-Learn: A Comprehensive Guide
Written on
Introduction to Predicting Patient Outcomes
In this article, we will create an application focused on patients suffering from heart ailments. Our tool will leverage Scikit-Learn, a widely used framework for machine learning. This guide will cater to both beginners looking to understand Scikit-Learn and experienced data scientists aiming to identify the optimal model for their data.
Dataset Overview
The dataset utilized in this project originates from a publication by David Chico and Guispe Jurman. Their research explores how machine learning can forecast survival rates of heart failure patients based solely on serum creatinine levels and ejection fraction. It is crucial to address common misunderstandings that beginners might encounter, as neglecting these could lead to significant issues down the line.
Understanding Scikit-Learn
Scikit-learn is an open-source library in Python tailored for machine learning tasks. It encompasses a range of algorithms and tools for data analysis and predictive modeling, including classification, regression, clustering, dimensionality reduction, model selection, and data preprocessing. Built on top of popular libraries like NumPy, SciPy, and Matplotlib, Scikit-learn is designed for seamless integration into machine learning workflows.
Key Features of Scikit-Learn:
- Algorithm Implementation: Efficient implementations of various machine learning algorithms, including support vector machines (SVM), decision trees, and k-means clustering.
- Data Pre-Processing Tools: Facilities for normalizing data, encoding categorical variables, and extracting features.
- Model Evaluation: Metrics for assessing model performance, including precision, recall, F1-score, and cross-validation techniques.
- Model Selection: Tools for automated model selection and hyperparameter tuning.
- User-Friendly API: A consistent and intuitive API that simplifies experimentation with different algorithms.
Scikit-Learn is a favored choice among the Python machine learning community.
Developing Models with Scikit-Learn
In this tutorial, we will explore how to construct several machine learning models, such as linear regression, KNN, decision trees, random forests, and support vector machines, specifically for predicting the mortality of heart patients.
To access the dataset required for developing these models, please follow the link provided.
Loading Data with Pandas
To illustrate data loading, we will utilize Pandas, which is essential for handling data frames. The dataset is separated by commas, so it’s critical to load it correctly to avoid issues.
import pandas as pd
# Load dataset
dataset = pd.read_csv("your_dataframe.csv", sep=",")

Using Pandas to Sample Data
We can sample our dataset using the head function in Pandas. It's important to note that understanding Pandas is crucial for the entire project. If you're unfamiliar with it and would like more content about Pandas, please comment below!
# Sample data
dataset.head()
Defining Features and Labels
We will create a matrix X for the features and a vector Y for the associated labels.
X = dataset.iloc[:, 0:-1].values # Features from all columns except the last
y = dataset.iloc[:, -1].values # Labels from the last column

Splitting Data for Training and Testing
When separating the training and test datasets, it’s vital to ensure that no future information is introduced into the training set during preprocessing. If you aim to estimate generalization error, you should use the test set only once!
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=1/3, random_state=seed
)

Validation Set Creation
We will divide the training set into two parts: one for training and another for validation. This helps in determining the most effective model. It’s imperative to only use the test set once to select the best model.
X_train_2, X_val, y_train_2, y_val = train_test_split(
X_train, y_train, test_size=1/3, random_state=seed
)
Feature Scaling
Most algorithms require features to be on a similar scale; hence, scaling is necessary.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
X_train_2 = scaler.fit_transform(X_train_2)
X_val = scaler.fit_transform(X_val)
Model Evaluation
Next, we will evaluate several models to find the best candidate. For simplicity, we will initially use a basic approach, but we will explore more sophisticated methods in subsequent sections.
from sklearn.metrics import accuracy_score
# Logistic Regression
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(random_state=seed)
lr.fit(X_train_2, y_train_2)
dic["Logistic_Regression"] = accuracy_score(y_val, lr.predict(X_val))
# KNN
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=7)
knn.fit(X_train_2, y_train_2)
dic["KNN_7"] = accuracy_score(y_val, knn.predict(X_val))
# Decision Tree
from sklearn.tree import DecisionTreeClassifier
tree = DecisionTreeClassifier(max_depth=4, random_state=seed)
tree.fit(X_train_2, y_train_2)
dic["Decision_Tree_4"] = accuracy_score(y_val, tree.predict(X_val))
# Random Forest
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=100, random_state=seed)
rf.fit(X_train_2, y_train_2)
dic["Random_Forest_100"] = accuracy_score(y_val, rf.predict(X_val))
# Linear SVM
from sklearn.svm import LinearSVC
svc = LinearSVC()
svc.fit(X_train_2, y_train_2)
dic['SVC'] = accuracy_score(y_val, svc.predict(X_val))
Evaluating Model Performance
We will summarize model performances in a validation series.
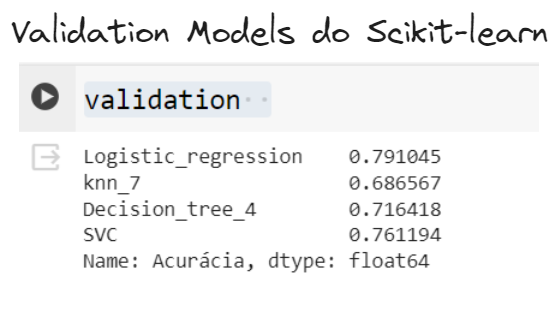
Final Model Training
Once the best model is identified, we can utilize the test set to estimate the generalization error.
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Training the best model
lr = LogisticRegression(random_state=seed)
lr.fit(X_train, y_train)

Conclusion and Next Steps
While there's potential for improving mortality prediction accuracy, I want to congratulate you for reaching this point. If you have any questions, feel free to reach out via email or leave comments below. Let’s keep the discussion about Scikit-Learn models going. Until next time!
Video Resources
To enhance your understanding of predictive modeling in healthcare, check out the following videos:
- Predictive Survival Analysis with Scikit-Learn: This video features Olivier Grisel discussing methods for predicting survival rates using Scikit-Learn, scikit-survival, and lifelines.
- Responsible Implementation of Machine Learning Models: This talk from Eindhoven explores the ethical considerations in deploying machine learning models for life-and-death decisions.