Exploring Top 3 Python Alternatives to Pandas for Data Analysis
Written on
Chapter 1: Introduction to Data Analysis with Python
For many contemporary data scientists, Python serves as the primary programming language for their daily tasks, with data analysis commonly performed using the Pandas library. Numerous online resources often present Pandas as the fundamental tool for data manipulation in Python.
While I still regard Pandas as the most beneficial and practical package for data analysis, this article aims to introduce a few alternatives to Pandas. My intention is not to persuade anyone to abandon Pandas but to raise awareness of the available options.
So, what are these alternative packages? Let's delve into them!
Section 1.1: Polars
Polars is a DataFrame library crafted for swift data processing, leveraging Rust programming and utilizing Arrow as its core. The main goal of Polars is to provide users with a faster experience compared to the Pandas package. It's particularly useful for datasets that are too large for Pandas but not substantial enough to warrant using Spark.
For those accustomed to the Pandas workflow, transitioning to Polars should feel fairly seamless—there are additional features, but overall, the two are quite similar. Let’s experiment with Polars! First, install the package in your Python environment:
pip install polars
Next, we can create a sample DataFrame using Polars:
import polars as pl
df = pl.DataFrame({
'Patient': ['Anna', 'Be', 'Charlie', 'Duke', 'Earth', 'Faux', 'Goal', 'Him'],
'Weight': [41, 56, 78, 55, 80, 84, 36, 91],
'Segment': [1, 2, 1, 1, 3, 2, 1, 1]
})
df
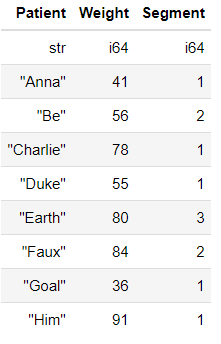
Like a Pandas DataFrame, the interface and workflow for data analysis in Polars are quite familiar. However, you'll notice that the data types are displayed at the top, and there is no index visible. Let's explore some of the functions available in Polars:
# Print DataFrame datatype
print(df.dtypes)
# Print DataFrame columns
print(df.columns)
# Print DataFrame top 5
print(df.head())
# Conditional Selection
print(df[df['Weight'] < 70])

Polars includes many functions that mirror those in Pandas, along with options for conditional selection. However, some functionalities from Pandas, such as index selection using iloc, are not applicable in Polars.
One unique aspect of Polars is the concept of Expressions. In Polars, you can create a sequence of functions (referred to as Expressions) that can be piped together. Here's an example to illustrate this:
# Parallel Expression
df[[
pl.sum("Weight").alias("sum"),
pl.min("Weight").alias("min"),
pl.max("Weight").alias("max"),
pl.std("Weight").alias("std dev"),
pl.var("Weight").alias("variance"),
]]
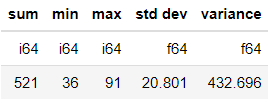
The primary advantage of using Polars is its superior execution speed. But how does Polars stack up against Pandas in terms of performance? Let's reference an example from Polars documentation that compares execution times.
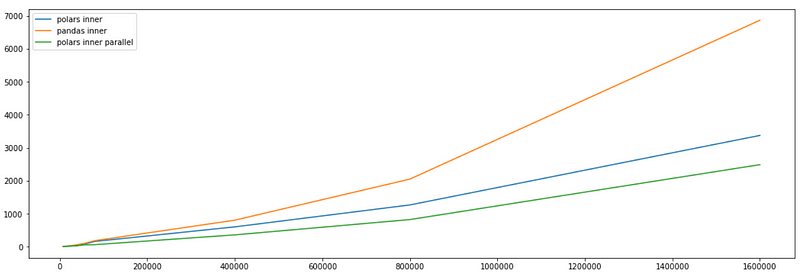
The image above illustrates the execution times for Inner Joins conducted through three different methods: Polars Inner Join, Pandas Inner Join, and Polars Inner Join Parallel. It's evident that as data size increases, Pandas tends to lag behind Polars in execution time.
Section 1.2: Dask
Dask is a Python library designed for parallel computing. It comprises two primary components: Task Scheduling, akin to Airflow, which optimizes computation by automatically managing task execution, and Big Data Collection, which provides parallel DataFrame structures similar to Numpy arrays or Pandas DataFrame objects.
In simpler terms, Dask offers DataFrame or array objects akin to Pandas, but processes them in parallel for enhanced execution speed, alongside a task scheduler.
In this article, we will focus on Dask's DataFrame functionality and not on Task Scheduling. Let's explore some basic Dask functions. First, ensure that Dask is installed (it is included in Anaconda by default):
python -m pip install "dask[complete]"
Once installed, we can initiate a dashboard to monitor data processing:
import dask
from dask.distributed import Client, progress
client = Client(processes=False, threads_per_worker=4, n_workers=1, memory_limit='2GB')
client
Dask provides a user-friendly dashboard that you can access after initialization. Clicking on the Dashboard link will reveal a comprehensive overview of your current Dask activities.
Let's create a Dask array, similar to what you can do with Numpy:
import dask.array as da
x = da.random.random((10000, 10000), chunks=(1000, 1000))
x
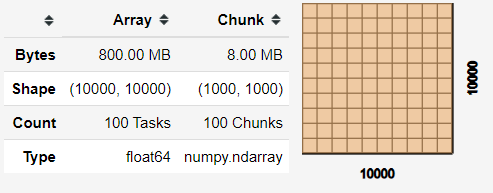
Upon creation, you'll receive matrix information as shown above, which serves as the foundation for your Dask DataFrame. Let's create a dataset from Dask for a more comprehensive example:
df = dask.datasets.timeseries()
df
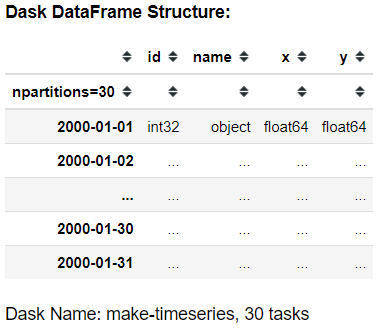
While the Dask DataFrame mirrors the structure of a Pandas DataFrame, it operates lazily, meaning it won't print data directly in your Jupyter Notebook. However, you can execute various functions that exist in Pandas on Dask. Here's how you can view the top five entries:
df.head()
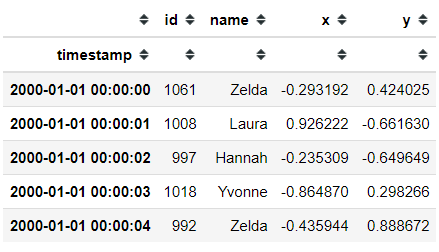
For conditional selection, the approach remains similar to Pandas, though it requires a specific function to execute:
df[df['x'] > 0.9]
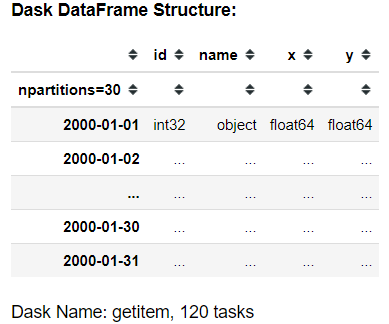
To convert the Dask DataFrame back to a Pandas DataFrame, use the .compute() function:
df[df['x'] > 0.9].compute()
Dask excels in parallel processing and is best suited for large datasets requiring significant computational power. If your data comfortably fits within your machine's RAM, it may be more efficient to stick with Pandas. For further exploration of Dask's capabilities, check their official website.
Section 1.3: Vaex
Vaex is another Python package designed for handling and exploring large tabular datasets, with an interface reminiscent of Pandas. According to its documentation, Vaex can perform statistical calculations—such as mean, sum, count, and standard deviation—on an N-dimensional grid at speeds reaching up to a billion rows per second. This makes Vaex a viable alternative to Pandas, particularly for improving execution speed.
The workflow in Vaex closely resembles the Pandas API, which means that if you're already familiar with Pandas, you'll find it easy to adapt to Vaex. To begin, install the Vaex package:
pip install vaex
After installation, you can try out an example dataset with Vaex:
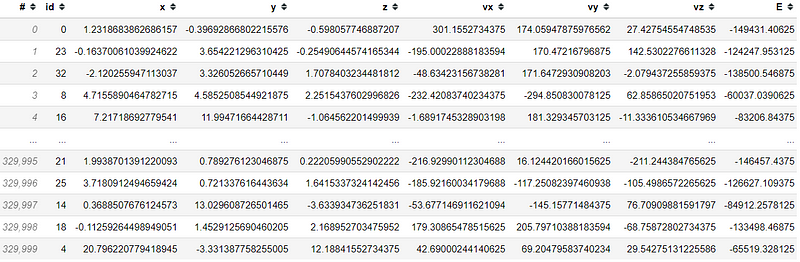
import vaex
df = vaex.example()
df
Just like in Pandas, conditional selection is straightforward:
df[df['x'] > 88]

A standout feature of Vaex is its efficient calculation of statistics on N-dimensional grids, which is particularly beneficial for visualizing large datasets. Let's see some basic statistical functions:
df.count(), df.max('x'), df.mean('L')

Moreover, Vaex offers plotting capabilities that allow you to apply statistical functions directly to visualizations. For instance, instead of using a simple count statistic, you can plot the mean of column ‘E’ while limiting the view to 99.7% of the data:
df.plot1d(df['x'], what='mean(E)', limits='99.7%')
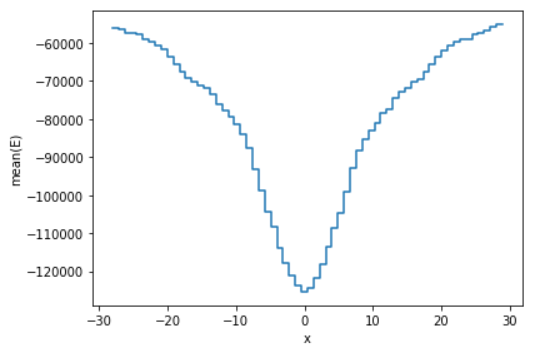
For more advanced plotting features, refer to the Vaex documentation. The key takeaway is that Vaex excels in rapid statistical computations and big data visualization. However, for smaller datasets, sticking with Pandas might be more appropriate.
Chapter 2: Conclusion
As a data scientist utilizing Python for analysis, you are likely accustomed to using the Pandas library for data exploration. However, there are several alternatives worth considering, especially when handling large datasets:
- Polars
- Dask
- Vaex
I hope this overview proves useful in your data analysis journey!
For further engagement, connect with me on LinkedIn or Twitter. If you're not already a Medium Member, consider subscribing through my referral link.