Enhancing Fairness in Machine Learning: Insights from Recent Research
Written on
Chapter 1: The Importance of Fairness in AI
In recent times, advancements in machine learning (ML) have allowed AI systems to play critical roles in decision-making processes across various sectors. However, it has become evident that these systems can exhibit biases that may lead to discriminatory outcomes based on race and gender.
Cynthia Dwork and colleagues introduced the concept of "individual fairness" in their 2011 paper, Fairness Through Awareness. They argue that an ML model is considered lacking in individual fairness if it treats similar inputs—defined as close according to a specific metric—differently, resulting in varying outputs or classifications. If no such pairs exist, the model is not deemed biased.
To address these concerns and enhance individual fairness in ML models, researchers from the University of Michigan, MIT-IBM Watson AI Lab, and ShanghaiTech University have published two significant studies: Statistical Inference for Individual Fairness and Individually Fair Gradient Boosting.
In the first study, Statistical Inference for Individual Fairness, the authors outline a statistically sound method for evaluating the individual fairness of ML models. They also introduce a collection of inference tools tailored for adversarial cost functions, allowing researchers to calibrate their methods, such as setting a specific Type I error rate.

The researchers describe their methodology as follows:
- Generating Unfair Examples: Unfair examples are defined as instances that resemble training examples yet are treated differently by the models. These examples are akin to adversarial examples but are permitted to differ only in designated sensitive attributes.
- Analyzing the Model's Behavior on Unfair Examples: They propose a loss-ratio based approach that is both scale-invariant and interpretable. For classification tasks, they introduce a variation based on the ratio of error rates.
The team employs a gradient flow method to identify unfair samples. The gradient flow attack solves a continuous ordinary differential equation, enabling the creation of an "unfair map." This map links data samples to areas within the sample space where the ML model's performance is subpar, thus pinpointing violations of individual fairness.
They assert that their test statistic, rooted in the unfair map, offers two primary advantages:
- Computational Feasibility: Evaluating the unfair map is manageable because integrating initial value problems (IVP) is a well-established field in scientific computing.
- Reproducibility: By algorithmically defining the test statistic, the researchers mitigate ambiguity in the algorithm and its initial conditions, thereby enhancing reproducibility.
To validate their approach, the researchers conducted a case study on the Adult dataset, utilizing four classifiers: Baseline Neural Network, Group Fairness Reduction Algorithm, Individual Fairness SenSR Algorithm, and a Basic Projection Algorithm. They compared group fairness using average odds difference (AOD) for both race and gender, with a null hypothesis rejection significance level of 0.05 and a parameter of ? = 1.25.
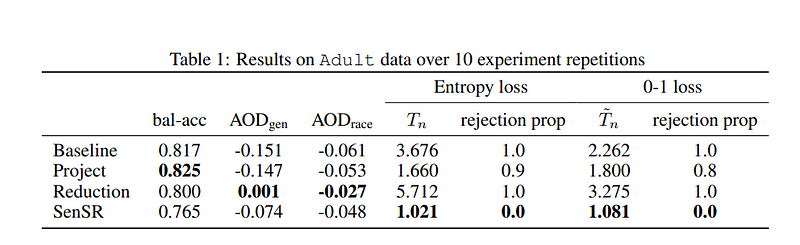
The findings revealed that the baseline approach did not meet the individual fairness standard, while the basic projection algorithm showed improvement, though it still did not pass the null hypothesis test. In contrast, SenSR successfully maintained individual fairness. These experiments highlighted the proposed tools' capability to uncover gender and racial biases in income prediction models.
Chapter 2: Gradient Boosting and Individual Fairness
The second paper, Individually Fair Gradient Boosting, emphasizes the need to uphold individual fairness within gradient boosting techniques. Gradient boosting is a widely used approach for tabular data that constructs prediction models by aggregating numerous weak learners, such as decision trees.
Existing methods for ensuring individual fairness often struggle with non-smooth ML models or demonstrate poor performance with flexible non-parametric models. The researchers' proposed solution is specifically crafted to accommodate non-smooth ML models.

The researchers outline their key contributions:
- They developed a method to enforce individual fairness in gradient boosting, specifically addressing non-smooth ML models like boosted decision trees.
- Their approach demonstrates global convergence, resulting in individually fair ML models. They also provide a means to certify individual fairness post-training.
- Empirical evidence shows that their method maintains the accuracy of gradient boosting while enhancing both group and individual fairness metrics.
This research aims to train ML models that are individually fair. The team enforces distributionally robust fairness, which posits that an ML model should perform similarly on comparable samples. To achieve this, adversarial learning techniques are employed to build an individually fair ML model resistant to adversarial attacks.
Additionally, the researchers explore the convergence and generalization properties of fair gradient boosting, revealing that it is feasible to certify that a non-smooth ML model meets individual fairness criteria by assessing its empirical performance differential.

They apply their fair gradient boosted trees (BuDRO) methodology to three datasets: the German credit dataset, the Adult dataset, and the COMPAS recidivism prediction dataset.
On the German credit dataset, BuDRO outperformed the baseline neural network (NN) in terms of accuracy while demonstrating the highest individual fairness score.

In the Adult dataset, the GBDT method remained the most accurate, although BuDRO showed slightly lower accuracy than the baseline. Nevertheless, it significantly reduced the gender gap and improved the accuracy of SenSR while maintaining similar individual fairness scores.
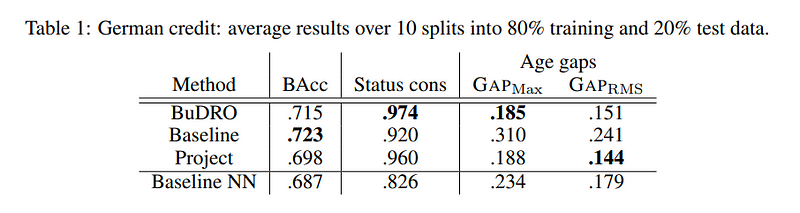
For the COMPAS recidivism prediction dataset, BuDRO achieved comparable accuracy to a neural network trained with SenSR, while outperforming it in terms of individual fairness, underscoring the effectiveness of the BuDRO strategy for ensuring individual fairness.
Overall, the researchers’ first study develops a range of tools for detecting and quantifying individual bias in ML models, empowering analysts to evaluate a model’s fairness in a statistically rigorous manner. The second study introduces a gradient boosting algorithm capable of enforcing individual fairness in non-smooth ML models while retaining accuracy.
Both papers, Statistical Inference for Individual Fairness and Individually Fair Gradient Boosting, can be found on arXiv.

Stay updated on the latest news and breakthroughs in research by subscribing to our popular newsletter, Synced Global AI Weekly, for weekly AI insights.
Explore the discussion on understanding and mitigating unfair bias in machine learning, featuring insights from industry experts.
Furkan Sezer shares striking insights on the consequences faced by users of illegal betting sites.